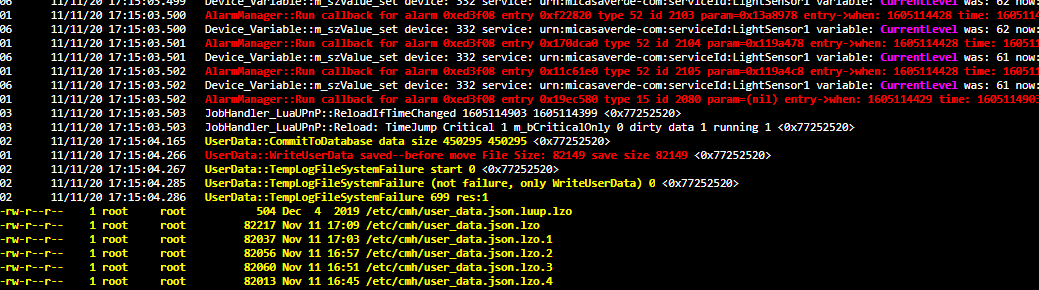
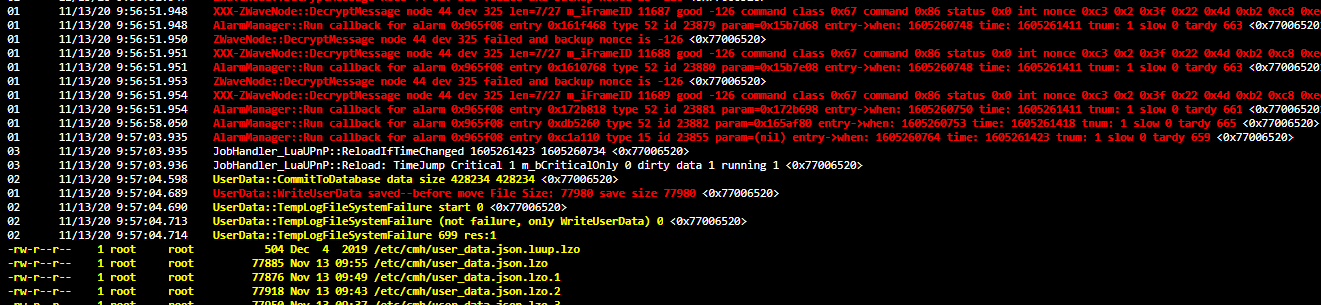
Didnt think I had changed anything but I noticed the below in the log
Time Jump critical, could this cause a Luup reload, if so anyone know what causes it, thank you in advance
Didnt think I had changed anything but I noticed the below in the log
Time Jump critical, could this cause a Luup reload, if so anyone know what causes it, thank you in advance
I did not have reboots but about 20 times today while I am at work, I was getting LUUP restarts. I did get a low battery warning in one of the devices around the same time. It settled down by the time I go home, I changed the battery, and I have not had a LUUP restart since 17:24 (now 21:21).
This reload is caused by time changed. It’s strange and it should happen only when time zone/daylight are effectively changing.
If you’re comfortable with ssh and co, you may try to fix the time service. There are plenty of examples in the forums.
I also suggest to open a ticket with support.
Hello
Thanks for the replies, @Sorin I have opened a ticket with support but not heard anything yet
I’ll check out I’m ok with ssh (just) whats co? please
I’m sorry, I was referring to ssh ![]()
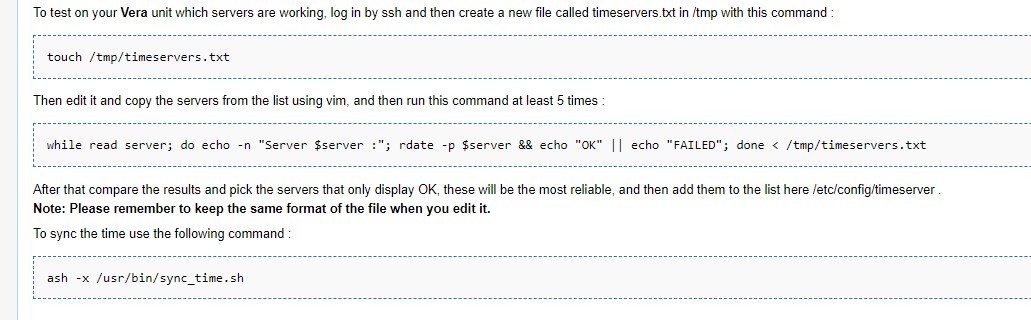
try to see if time is OK, what time server are specified, and such.
Time Syncronization - MiCasaVerde
Vera Edge and ntp (firewalling vera completely from the internet) (micasaverde.com)
ok great thank you, I will have a look but it grieves me I have to do all this fiddling around, I dont have time to watch films anymore I spend half my life looking at the luaupnp log ![]()
![]()
and another one just happened
Great Start
rdate not found
rdate should be removed from latest fw. Everything else should be still valid.
Ok so created the file with touch
But there is no file /etc/config/timeserver - it doesn’t exist
Not going to do anymore I’ll have to wait for support, thanks anyway
And two more reloads
@Sorin
Ok so I opened a ticket over a week ago, got a reply yesterday saying they needed to call me and to give them 6 hours notice, I confirmed yesterday for them to call me at 19:00 GMT today its now 19:23 and I have heard nothing, I’m sitting by the phone and computer waiting, please advise?
Ok couldn’t sit around any longer so I made the international call into support the original lady was off today, so fair enough and I did ask her to confirm but she didn’t so again fair enough
Anyway got through on the phone straight away the lady removed the user data file and I think she said dongle file, and replaced them with the originals, I restored the back and fingers crossed its sorted…waiting with baited breathe!
Thanks
The information on these two links is way out of date and doesn’t really apply any more.
On current Plus/Secure/Edge systems, to see the time server configuration, you do this:
uci show ntpclient
The typical time servers now are x.openwrt.pool.ntp.org (where x is 0-3), which are pools of time servers. It’s very unusual for any of these well-known servers to be off.
Any lapse of Internet access can cause clock problems, because time cannot be synced. Firmware older than 7.31 also restarts more often during Internet access outages, and this, by definition, breaks the clock and invariably causes TimeJump reloads later, so it’s very important to understand the recent history of the system and the network; you can’t just look at a TimeJump alone in the logs and make any determination from the single data point. You need to know what’s been going on before that.
@Nevillebriggs the log snippet you posted shows that your clock slewed more than 10 minutes, which is probably what caused the reload (small adjustments of a minute or two don’t seem to cause reloads – I haven’t tested extensively to find exactly where the tipping point is).
Is this happening a lot, or just once in a while? Did you have an Internet access outage? What else was happening with the system?
Thanks for the reply, the reloads were random so two this evening within 1 hour then 1 yesterday then it may go for a day…its possible the internet was dropping , have just upgraded with a new router and its still happening, im going to leave it alone and see whether support have solved it they reckoned the userdata file was corrupt…i couldnt pinpoint anything that was happening
OK. Obviously reloads can occur for many reasons. When looking for them in the text of the log file, the lines have the string “::Reload” usually have the reason code associated with them, but always post a few dozen lines from before as well, to give more context.
Also, you can track the status of your Internet connectivity within Reactor by looking at the NetworkStatus state variable in the Reactor master device. It will be 0 when there’s no Internet access. If you just set up a condition on that device/state that does nothing (no activities), you can at least use the Status display to monitor the timestamps of changes in its state, so you’ll know when Reactor thinks the Internet has gone away. That may be useful in determining if you are having an intermittent router or connectivity problem.
Great idea thanks, it was the reactor logs and you pointing out the reloads a few weeks that helped and i set up sensor for luup reloads which also helped, anyway thanks ill give it a go
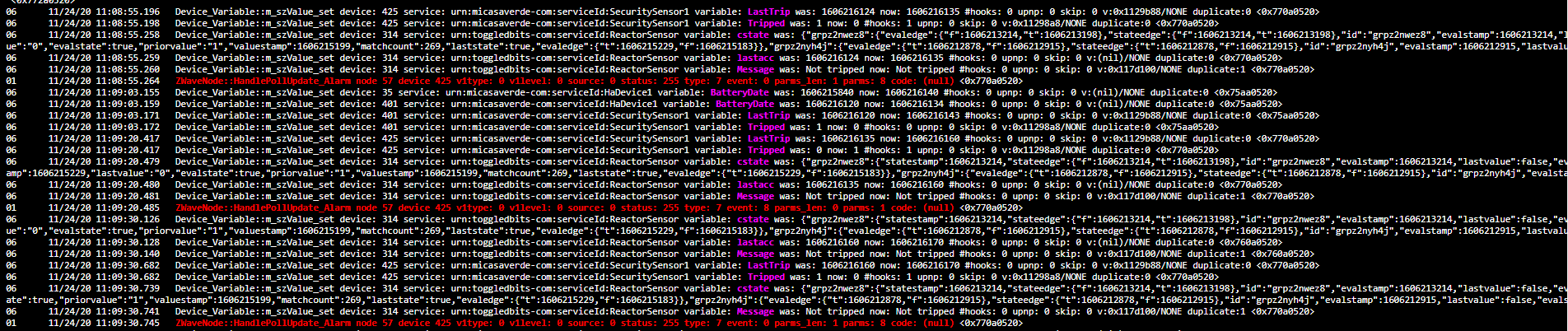
OK I know this is a big ask but here’s the log, The connection to the internet has been up 6 days this is the first time critical reload in 4 days after support replaced my user data etc
There may be other reloads in the log but they were instigated by me, for example the sensor in the study did not turn on the lights this morning so I reloaded and it worked fine
luaupnp log.zip (125.2 KB)
for ease the time jump happened at 11/23/20 10:15:31
Thank you for any help you can give
This TimeJump is odd, because it doesn’t actually seem related to time, although it logs as such. The reload message is reporting that the time jumped 8 minutes (exactly), yet there is no evidence of this anywhere in the logs – it shows a flow of unbroken time from its start at nearly 45 minutes earlier that seems pretty normal, even after the reload. Yet it somehow believes that some internal marker it keeps for the current time and the system’s reported time were 8 minutes apart. More often when you see a TimeJump reload, you can go back in the logs just a little bit and find a gap in time in the log timestamps, making it clear. This shows no such gaps.
So then I think, “Did something get recorded and stuck exactly 8 minutes before the reboot?” The logs show one of several bursts of Luup trying to communicate with device 460, labeled “Fib test”. A big burst at 8 minutes exactly prior to reload, but many bursts as well. There are lots of runs of red text associated with this device, and it looks like it’s having a rough go communicating with it. In fact, going through references in the log to that device, it looks like there’s an issue more often than not when it tries to communicate with it. There is also evidence of some trouble communicating with device 325, labeled “Hall Motion Sensor”. It looks like both of these devices are in secure mode. And both Fibaro.
In the absence of any assistance from Vera support, if this were my system, I would start with 460 by excluding it and seeing if my system stabilizes. If not, I would exclude 325, and so on, until the logs were a healthier color and I could get longer runtime. I recognize that is removing devices that are likely tied to automations and functionality you want to keep, but as they say, if you want to make an omelet you have to break some eggs… in the course of debugging, it is sometimes necessary to take things apart to eliminate variables and make the problem show itself more clearly. Once you have a stable system, you can slowly start re-introducing those devices… maybe every other day or longer, take a full backup (with ZWave backup) first, then add one device, and carefully (examining logs, diligently observing system behavior, etc) see how it goes. Also, if there’s a way to include them not in secure mode, I would do that.
As for the TimeJump, I’m guessing there may be something about the way they do secure negotiation where they have to record a position in time as a reference. Somehow after an error, that position is not being updated (maybe it gets locked and isn’t unlocked by the error exit path, or is left with some damaged value), and that later leads to a TimeJump reload. Who knows. Without having code to inspect, it’s all just a W.A.G.
And why am I not surprised that all the red text is associated with a Fibaro device?
Thank you for the analysis,I’ve been running on about these sensors in another thread (Fibaro and Neos) and decided last week that I was going to replace them all with the Aeotec Trisensor or the Hue which seem to work correctly reporting lux temp and untripping
However yesterday I thought I might keep some of the Fibaros and I added back a Fibaro yesterday and called it Fibtest I have been checking to see if it untrips which it has been ok BUT I think you have hit the nail on the head I’m going to remove it now and see what happens, if I get anymore reloads I’ll remove the other one and start debugging
Thank you
Best Home Automation shopping experience. Shop at Ezlo!
© 2024 Ezlo Innovation, All Rights Reserved. Terms of Use | Privacy Policy | Forum Rules