It will happen from time to time, depending upon the release you’re using. If MiOS “detects” that something is amiss, it will “kill” off everything and cause it to restart.
Technically, it should never need to do this, but it has the above mechanisms to prevent problems resulting from memory leaks, bugs (etc). If they’re occurring very frequently then you can often work out what’s going amiss by [periodically] looking at “top” and working out which bit is leaking memory (most common cause from what I’ve seen)
Over 8 years later and… this seems to be still my first source of luup reloads. It is currently correlated to me upgrading firmware of a network switch. At least it is the case this morning but I often can’t correlate it to anything happening in the house. It is not very frequent, once every few days or weeks. It is not a memory leak, I am far from being out of memory or storage. I have no extensive plugins on the vera either.
Having dug further into what could cause this, I am now highly suspecting that there is a command queueing error to the serial z-wave interface.
I know the eZLO devs are working on a new platform but I have not seen the color of it yet. @melih, @Sorin:
Just in case this could be useful for your new platform, I think the main source of luup reload is a lack of error handling in the zwave command queue. I am seeing in my logs a number of unexpected responses from some devices which I think makes the luup engine thinks that these devices did not respond. It seems like just before I get a luup reload, I also get very long lags in responses from luup commands which indicates that either the luup engine or more likely the zwave dongle/serial is busy waiting for something or processing something and ends up hanging with a timeout which then leads to the vera doing a reload and miraculously works again. The fact that the reload recovers it hints though that something between the luup engine and the serial interface is out of sync. It is pretty rare as it occurs randomly at interval of a few days to a few weeks but it is definitely a problem.
I hate to toot the horn of another system, but while the eZLO team is busy rebuilding this firmware, the behavior of many competing systems is that Z-Wave is handled in such a way that it is possible to restart/reset the Z-Wave dongle and restart Z-Wave processing without a restart of the entire system–a subsystem restart, isolated. It will always be the case that interface hardware goes wrong. Just as network devices recover by re-opening sockets and re-authorizing when an existing connection times out or is closed suddently by the far end, so too should the Z-Wave radio be handled. My 2p, and a hope that eZLO engineering has considered this approach for the future.
So that it’s said, this doesn’t make up for good error recovery and doing everything possible to avoid even the subsystem restart–it’s a last-resort response–but it shouldn’t be necessary to nuke and rebuild the entire world in any case.
I’ve reported this to the old engine team. In fact this was a known issue at a certain level, but very hard to reproduce and fix. We’re just hoping we’ll have enough time to catch this issue part of the next firmware.
I was going down the wrong track I believe with the time keeping of the OS causing the luup reloads. I am noticing in the logs that the zwave commands show a parameter called “tardy” and that this parameter goes up and down (according to how busy the zwave dongle is). It appears that I get a luup reload whenever the “tardy” time exceeds something like 320 or 360 which is when I am observing the zwave commands lagging. It appears to be the time between when the vera expects a response and when it gets it. I am also getting a lot of “got CAN” errors for specific dimmer commands which I don’t know the impact of.
This is the error I see when I get a reload and in this particular case I had a code 137 which is a self triggered reload by the Luup engine.
So do you think this tardy time is in tenths of a second? If so that would make a lot of sense. 30 seconds is the magic number on luup reloads due to ‘deadlocks’. It is also the max time RTS always advised it might take for z-wave confirmation - although with the latest firmware I occasionally see longer…
I actually think it is in full seconds. When I grep “tardy”, all the messages are about alarm callbacks. It appears that the tardy shows a gap in time between when a variable is set and when it actually gets feedback for it. It is very very long during a heal for example. Under normal usage I have seen it go up to 100s (I sometimes see this long of a lag to switch a light on for example) but then it can suddenly decrease down to 0. When it is 0, the tardy term actually completely disappears and you get no log entry.
My zwave network is very active (HEM constantly reporting and my HVAC custom plugin is adjusting vents and thermostat state every minute) so I am able to observe the tardy number build up and drop. It is indeed when that number exceeds 300 (5min!) that I get a luup reload. The cause of the lag remains a mystery. I am still trying to figure out why such lags can occur. I also noted a “critical only” flag which gets turned on and then back off during a luup reload which looks like it prevents the luup engine from reloading itself while it is already reloading. Why a luup would resolve the lag is also a mystery as it would indicate that the lag is unrelated to the state of the dongle but rather some command queuing overload on the vera side. Also the fact that other controllers which have a command queue handle this much better is an indicator of a vera specific problem caused back the lack of command queue within the controller software.
I had another exit code 245, 2nd one this week in spite of now only running 11 zigbee devices on the vera so I figured I would do another search and found my own ancient posts here as well as a litany of posts dating from 2010 discussing this error code and am stunned that it still hasn’t been figured out.
No memory problem. No zwave overload. I am still getting this reload error code.
For the record, I learned quite a bit since my post above and the tardy log entry actually disappears when the delay is <4s. The tardy callback is due to a delay in processing of a command in the luup engine and is specific to the zwave command queue in my case. The delay in execution is completely self induced and avoidable and I have traced it back to disgusting race condition avoidance patches which are lazy coding to avoid figuring out and solving the source of the race conditions. Instead the path chosen was to wait and delay commands or worse yet, disconnect and ignore from the zwave serial API for some time. This type of code should never have been more than a short term test to validate a problem source. It should never have been implemented in production and is certainly not a viable solution to anything! These delays just accumulate, staggering on top of one another and eventually cause the luup engine clock to be out of sync with the OS time which causes a luup reload.
Now back to the exit code 245 which remains a mystery… and is the reason why I will move my zigbee devices to another platform as well.
And we still don’t know what “LuaUPnP Terminated with Exit Code: 245” means or how to investigate with an eye to prevention. I am not sure if I will make it to Elzo Firmware, but if I do, I expect better error handling and documentation.
I recently had this problem on my Vera Plus, looking in the Vera log I could see these errors:
“LuaUPnP Terminated with Exit Code: 245” and “LuaUPnP crash”
I was editing some IP camera variables on my Vera Plus, and then I lost access to it in the browser, it said “Luup engine is taking longer to reload.” and the GUI was not loading up in the browser.
Looks like my user_data.json.lzo got corrupted.
I used WinSCP to connect to Vera and in the etc\cmh folder I renamed the file user_data.json.lzo to something else and then renamed one of the backup user_data.json.lzo.5 files to user_data.json.lzo and rebooted Vera via SSH and it was all back up and running again OK.
Vera user since 2013 with a rather big setup. In our house I have 2 Vera Edges to control a lot of things. One is with 60 zwave nodes and quite some Hue lights (via Hue plugin of @amg0). All logic is done via the great Reactor plugin of @rigpapa, I don’t use any Vera scenes anymore. This Vera Edge runs rock solid for almost 2 years. Usually once per day there is a luup reload but always online and functioning okay (sometimes I experience some delays in lights turning on or off)
On the other Vera Edge there are no zwave devices at all. On this one I run 12 Sonos devices via Sonos plugin, 3 SiteSensor (another great plugin of @rigpapa) devices for actual weather and weather prediction (I have a PWS connected to Wunderground), Dutch Smartmeter plugin of @reneboer RFXcom via RFXTRX plugin of @tinman to read my watermeter, and 4 camera’s (Doorbird doorbell, Vistacam and 2 cheap D-Link). All logic is done via Reactor plugin, Switchboard plugin and Multistring plugin.
Although I checked the memory and there seem to be no memory leaks I run
every night a Lua code (found on this forum) to clean up the memory and reboot the controller.
On this Vera Edge I do have frequent luup reloads (minimum 3 per day, usually during the night at the same times 5:12 5:13 6:32 but sometimes more than 10 per day. And once per week or per 2 weeks the controller does not come back online. I have to powercycle it to get it running again. Which is very annoying.
I looked at the logs. I don’t understand everything but what I notice:
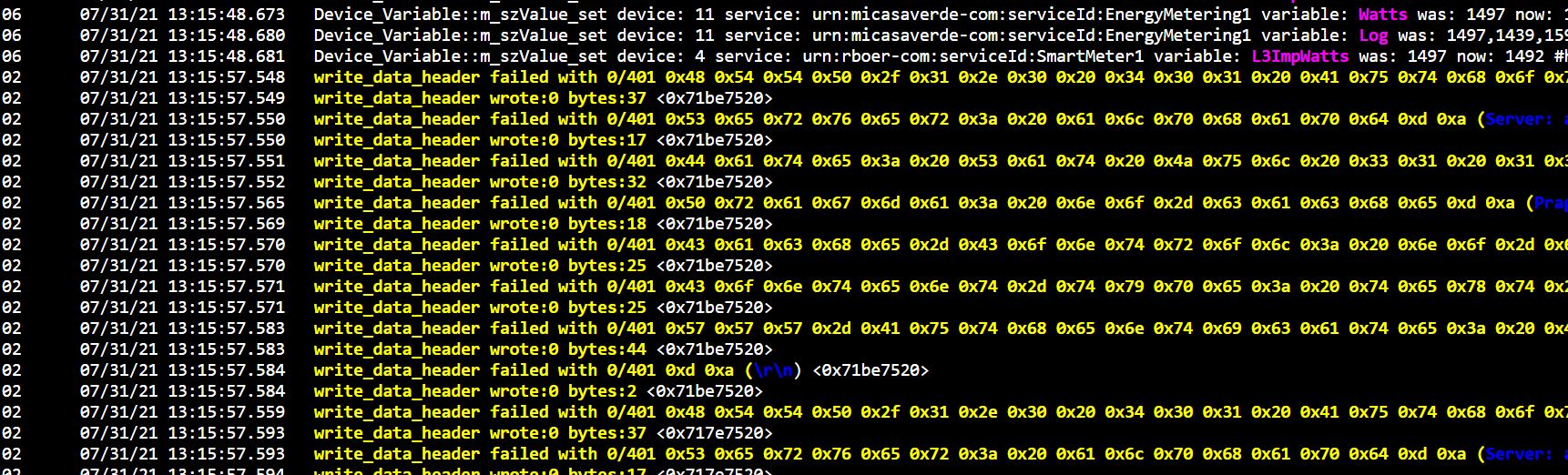
1. Every minute “write data errors” those have to do with the camera’s
Screenshot:
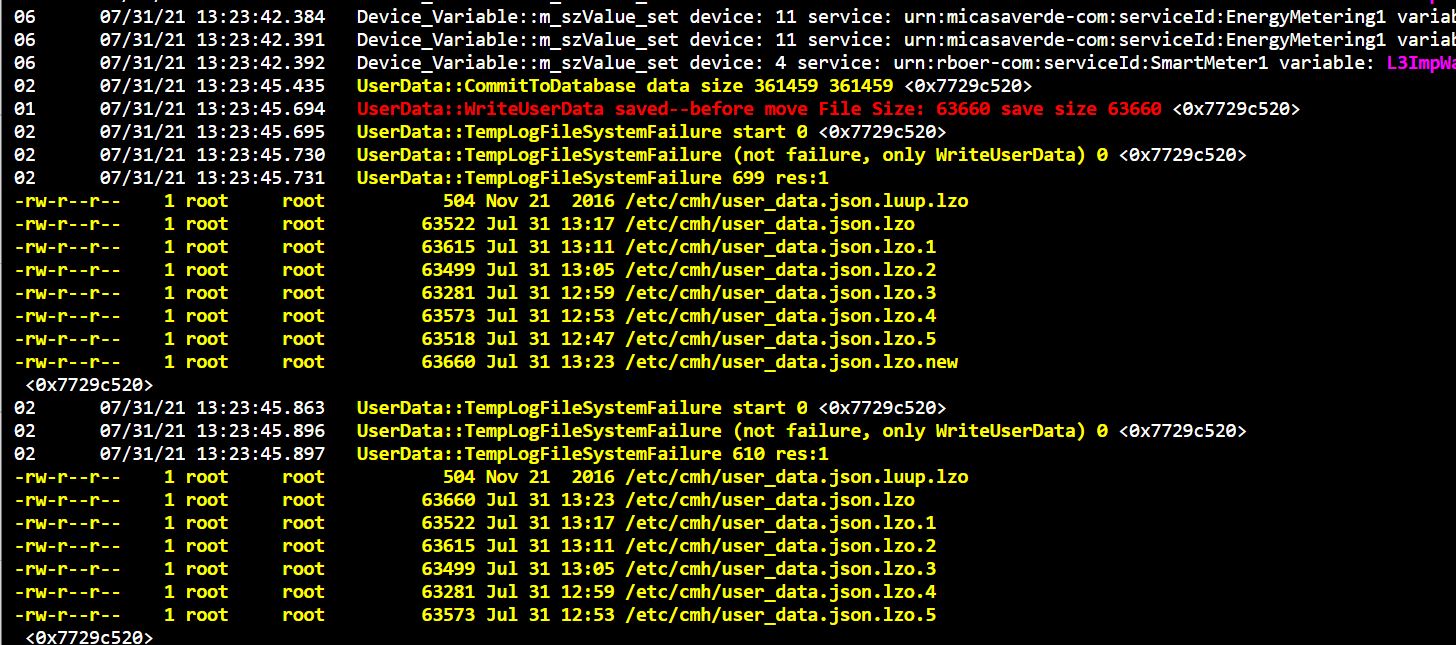
2. Every 5 minutes “userdata failure” no clue what it means
Screenshot:
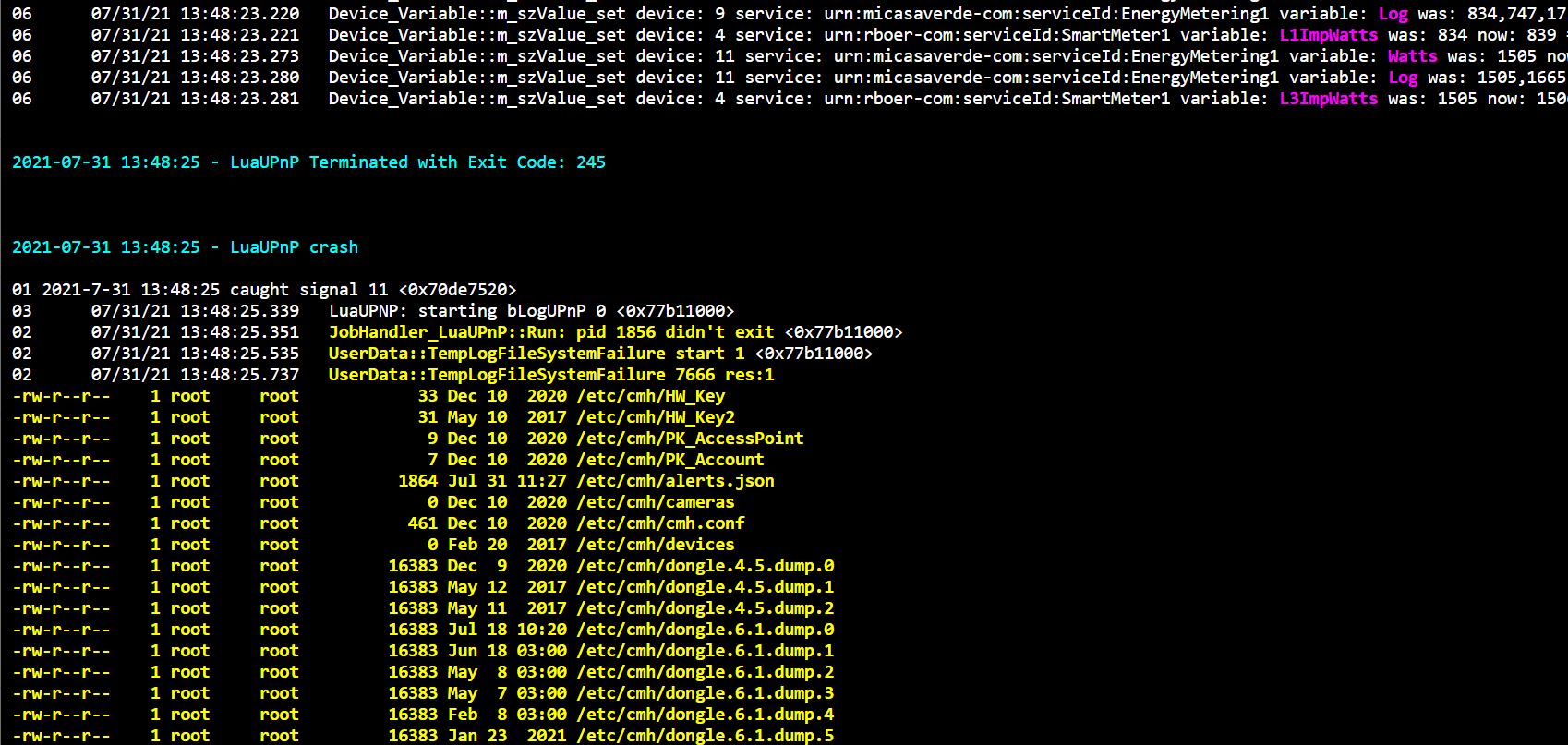
3. When Luup reloads I see LuaUPnP Terminated with Exit Code: 245 and LuaUPnP crash
It seems to happen out of the blue, no yellow or red lines just before it happens.
Screenshot:
So this exit code 245 has nothing to do with busy zwave queue
But what is the reason ? And how can I prevent those luup reloads and more important how can I prevent the controller going offline ?
Are the problems caused by the camera’s ?
Or too much traffic reading all the weather data (every minute) and smartmeter data (every 5 seconds) ?
Would it help to use a Vera Plus in stead of Edge (I have one that I use for testing).
I hope some of the experts left on this forum (not switched to another platform or banned) can give me some good advice. @rigpapa@therealdb@reneboer or others ?
Or maybe someone from the Ezlo team ???
7.32 beta is definitely more stable. Give it a try.
Long term I’ll move the load off the non-Zwave Vera to an openluup install. The mentioned plugin will be ok and it will be stabler, given the more power you’ll get.
If you are only running plugins and no Zwave devices on this Vera you could also consider a PI3 or 4 with openLuup. I use that for a number of the same plugins and runs solid for months on end.