So after support failed to fix it last time and just ignored me, I excluded and re-included the Fibaro FGBS321 again.
This was about 6 weeks back at most.
Again one of the temperature sensors has stopped responding, but this time the logs might be a bit different:
I don’t think it’s the command class. There’s 3 other identical sensors attached to that fibaro. All working perfectly:
24 02/23/19 16:32:49.411 ZWaveNode::HandlePollUpdate node 35 device 115 class 0x31 command 0x5 m_iFrameID 464/26204720 data 0x1 0x44 0x0 0x0 0x5 0x3f (#D###?) <0x77172520>
24 02/23/19 16:32:49.412 ZWaveNode::HandlePollUpdate_SensorMultiLevel_MeterReport 0x31 node 35 device 115 child 0/0 cat 17 embed: 0 type 1 rate type 0 is 13.430000 was 13.500000 prec 2 sca 0 size 4 delta -1 previous -1.000000 len 6 <0x77172520>
So the class seems fine.
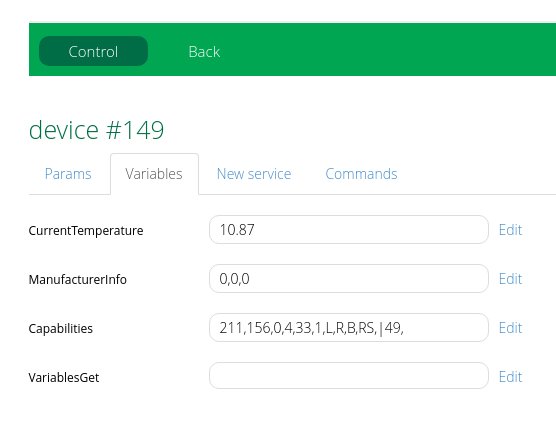
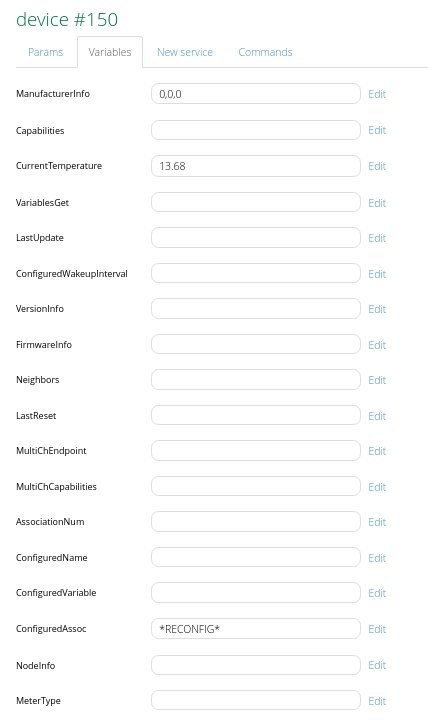
Perhaps worth noting that the failed senor has a stack of variables assigned to it. They are all empty apart from as shown (Capabilities was empty. I copied from 115 in the hope of making it work)
The one that seems most important is ConfiguredAssoc: RECONFIG
recover from a backup prior to the sensor failure without zwave recovery. This would be a corruption of the vera user-data.json. Not uncommon. Mostly due to a luup crash/reload at the wrong time.
reconfigure the device which may delete and regenerate child devices (it’s dumb I know). If you have automation on using these child devices, you can always renumber the child devices after it’s done. The cause for this would be corruption of the zwave dongle data.
If 1 and 2 fail, power cycle the fibaro. This would be a device self corruption.
All of those may well fix the issue, but I can’t really say they are acceptable solutions. If the system isn’t reliable, for what are we paying?
I’m not even sure how I can tell when the crash happened so I can deal with 1) The logging and rotation is so messy.
I’ve just gunzipped my oldest log from 20th Feb and the issue is there, so now I have no idea when the issue started
Could be… Looks like it was problem 1… You got your user data corrupted. Either you have a failing flash which means that your vera is dying, in which case extroot is the only way out before you get some other problems, or you just have some luup crash/reload to address.
Hi, I agree with the comment. I have the same problem. Once per month one of my sensor gets in stuck. When I check it, the reason is that “variables” → ConfiguredAssoc RECONFIG. It’s a strange because the same second device has absolutely another configuration and doesn’t have such field at all. Usually I recovery my system from backup, but after one month already another sensor gets in stuck. I noticed that usually it happens more often with sensors which send temperature (or consumption) data more frequently. If I reduce a frequincy data exchange then they don’t get in stuck anymore. I think that it is a problem with VERA. Please see below two pictures, the first (#149) is OK, the second is the same sensor (#150) but is in stuck.